Archived snapshot (pulled from commit a6ddeef, 2025-11-09).
Historical version preserved from the earlier crowdlistening.md lineage.

From Content Aggregation to Original Research (crowdlisten.com)
Crowdlistening transforms large-scale social conversations into actionable insight by integrating llm reasoning with extensive model context protocol(MCP) capabilities. While being able to quantatively analyze large volumes of data is already an interesting task, our focus is not just on content analysis at scale, but rather conducting original research directly from raw social data, generating insights that haven’t yet appeared in established reporting.
Deep research features provide professional-looking research reports, yet the contents are far from original, as they’re drawn from articles already indexable on the internet and paraphrased with LLMs. However, much of the internet’s data exists in unstructured formats - TikTok videos, comments, and metadata, for example. Too much content is generated every day for there to be existing articles written about it all, and when such articles are published, they’re often already outdated. When you consider multimodal data, metadata, and connections between data points, these are precisely the types of information that could yield genuinely interesting and useful insights.
I’ve been thinking about this problem while working at TikTok, enabling better social listening through more fine-grained insights extracted using multi-modal/LLM-based approaches. In October, I started developing early conceptions of Crowdlistening, focusing on multi-modal content understanding for TikTok videos. Although deep research features like GPT Researcher and Stanford Oval Storm existed, it wasn’t intuitive to integrate unstructured data processing capabilities into their workflows.
I paused Crowdlistening in Winter Quarter due to other commitments, but during this time, Anthropic released the Model Context Protocol (MCP). I’ve recently gotten back on track following progress in this field, and I believe this presents an interesting avenue for product innovation - deep research features are significantly enhanced by the growing ecosystem of MCP servers (the same agentic workflows perform much better given they rely on APIs, whose capabilities have improved over recent months).
What I’m particularly interested in exploring and building with Crowdlistening is the ability to extract actionable insights from large volumes of unstructured or semi-structured data, forming linkages, and perhaps even testing hypotheses to enable effective research at scale. We started with TikTok data as a prototype ground given my familiarity with the medium, but I could quickly see this covering any type of unstructured data available on the web.
Product Suite Overview
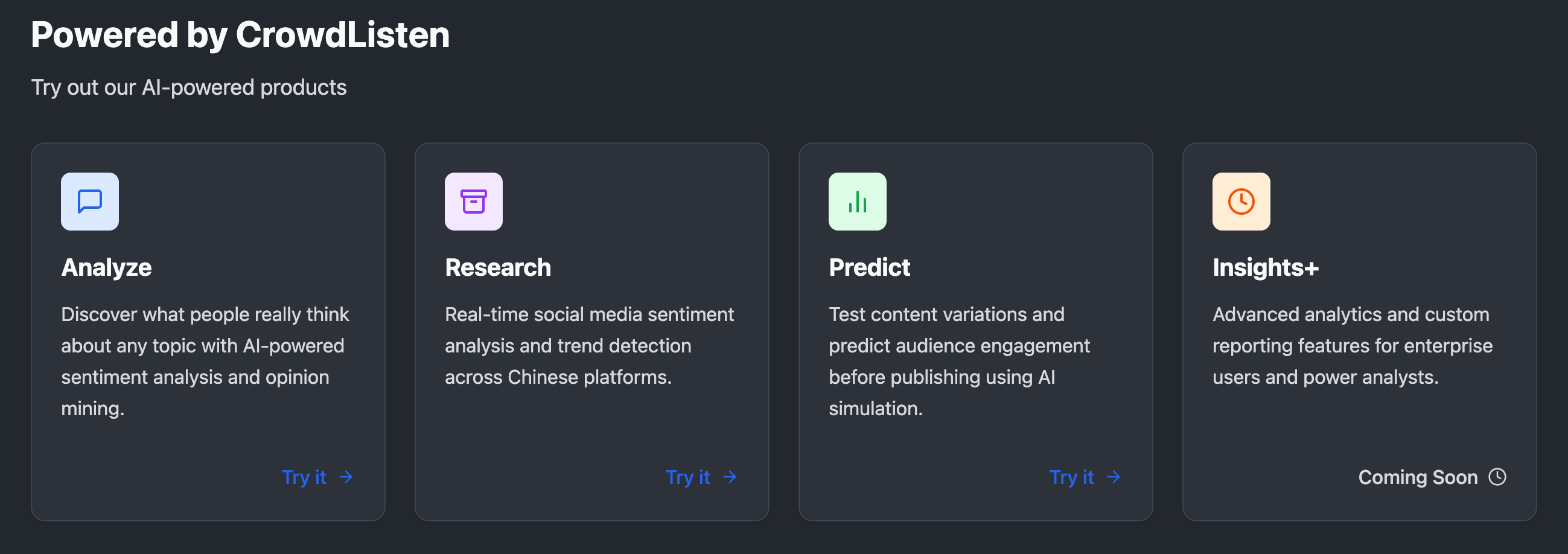
CrowdListen has evolved into a comprehensive suite of AI-powered products designed to address different aspects of social intelligence and content strategy. The Analyze product serves as our core offering, enabling users to discover what people really think about any topic through sophisticated AI-powered sentiment analysis and opinion mining capabilities. This goes beyond simple positive/negative categorization to understand nuanced perspectives, emotional context, and the underlying reasons behind audience reactions.
Our Research product focuses on real-time social media sentiment analysis and trend detection, particularly across Chinese platforms where traditional Western tools often fall short. This capability is crucial for brands and researchers who need to understand global conversations and cultural nuances that might be missed by region-specific tools.
The Predict product represents our foray into predictive analytics, allowing users to test content variations and predict audience engagement before publishing. Using AI simulation technology, teams can experiment with different messaging approaches and understand likely audience reactions without the risk and cost of live testing.
Finally, our Insights+ product caters to enterprise users and power analysts who need advanced analytics capabilities and custom reporting features. This tier provides the depth and customization necessary for organizations making strategic decisions based on social intelligence data.
The Insight Paradox

Brands today face a fundamental paradox: they need broad insights from vast amounts of social data, yet require the detailed understanding typically only available through limited case studies. Current solutions offer either abstracted metrics that require tedious manual interpretation, expensive and limited content screening that can’t scale, or surface-level sentiment analysis that misses nuanced opinions. Crowdlistening bridges this gap by combining the scale of algorithmic analysis with the depth of human-like comprehension. This addresses the first challenge identified in “Essence of Creativity” - helping users understand massive amounts of information and generate meaningful insights when they “don’t know what output they want.”
Technical Architecture: Multi-Modal by Design
The rationale behind Crowdlistening’s multi-modal technical architecture stems from the fundamental challenge of extracting truly valuable insights from the vast and varied landscape of online conversations. Traditional methods often fall short because they either focus on structured data or analyze individual modalities (text, video, audio) in isolation. This approach misses the rich context and nuanced understanding that arises from the interplay between different forms of content and engagement. For example, a viral TikTok video’s impact is not solely determined by its visual content but also by its accompanying audio, captions, user comments, and engagement metrics like likes and shares.

Crowdlistening’s design directly tackles this limitation by integrating embedding-based topic modeling and LLM deep research capabilities to process and understand this multi-faceted data. Embedding-based topic modeling efficiently identifies key themes across massive datasets, while the LLM’s deep reasoning capabilities can then analyze these themes within the context of various modalities.
This dual approach allows for a layered analysis, examining both the primary content and the subsequent engagement it generates. By processing video, audio, text, and engagement metrics in a unified system, Crowdlistening can generate insights that reflect not just what is being said, but how it’s being said, the surrounding context, and the audience’s multifaceted response. This comprehensive understanding is crucial for overcoming the “insight paradox” and delivering truly actionable intelligence that goes beyond surface-level sentiment or abstracted metrics. Ultimately, this multi-modal design is essential for achieving the core goal of Crowdlistening: to conduct original research directly from raw social data and uncover emerging trends and nuanced opinions that would be invisible to single-mode analysis systems.
Detailed Analysis Capabilities
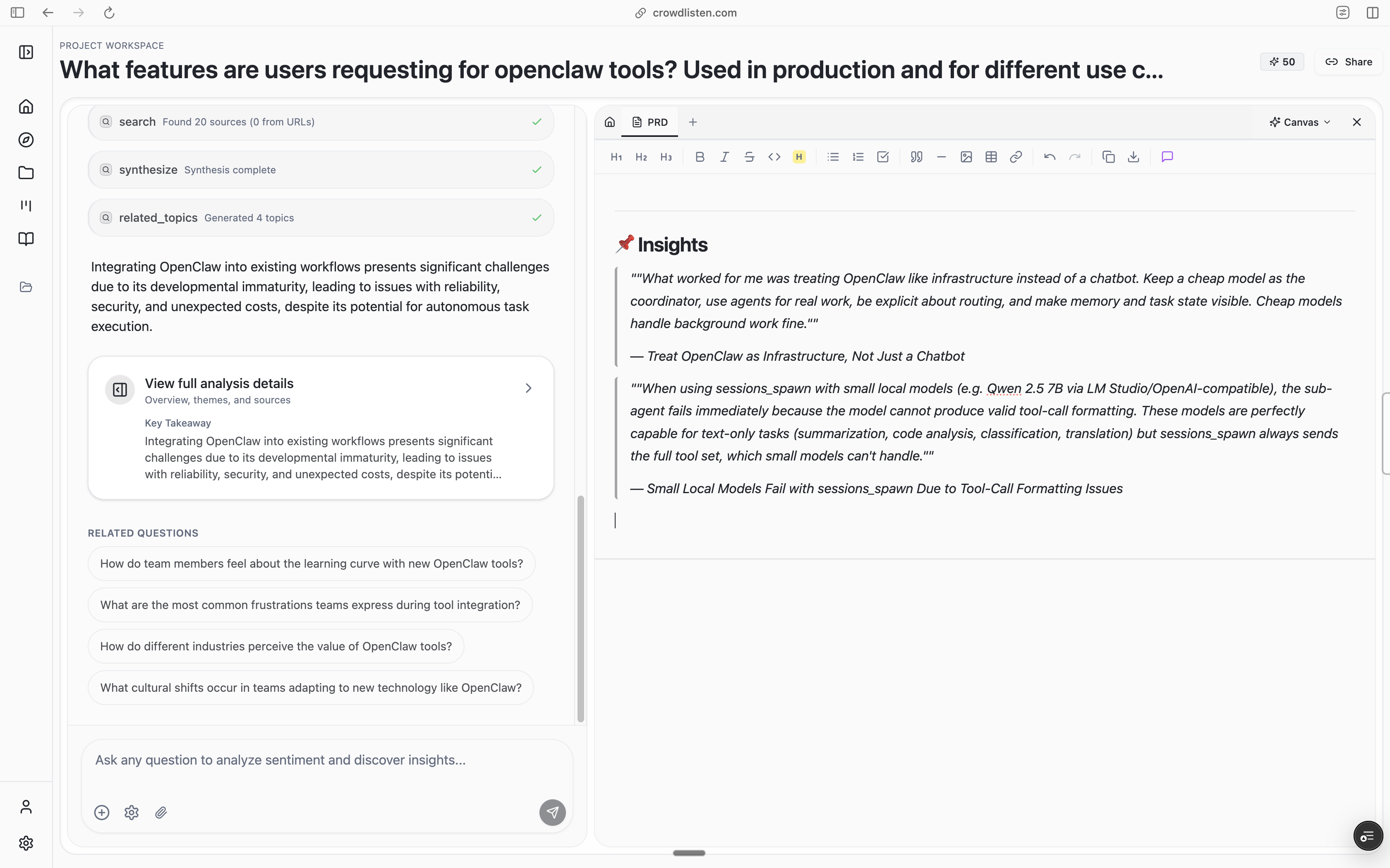
The platform provides granular breakdowns of content performance and audience reactions. As shown in our analysis results page, users can explore specific themes, track sentiment over time, and identify the most engaging content types. This helps brands understand not just what is being said, but why certain content resonates with their audience.

The opinion analysis feature goes beyond simple positive/negative sentiment to categorize specific viewpoints and concerns. This allows brands to understand the nuanced perspectives their audience holds, helping them craft more targeted and effective messaging.

Advanced Research Infrastructure
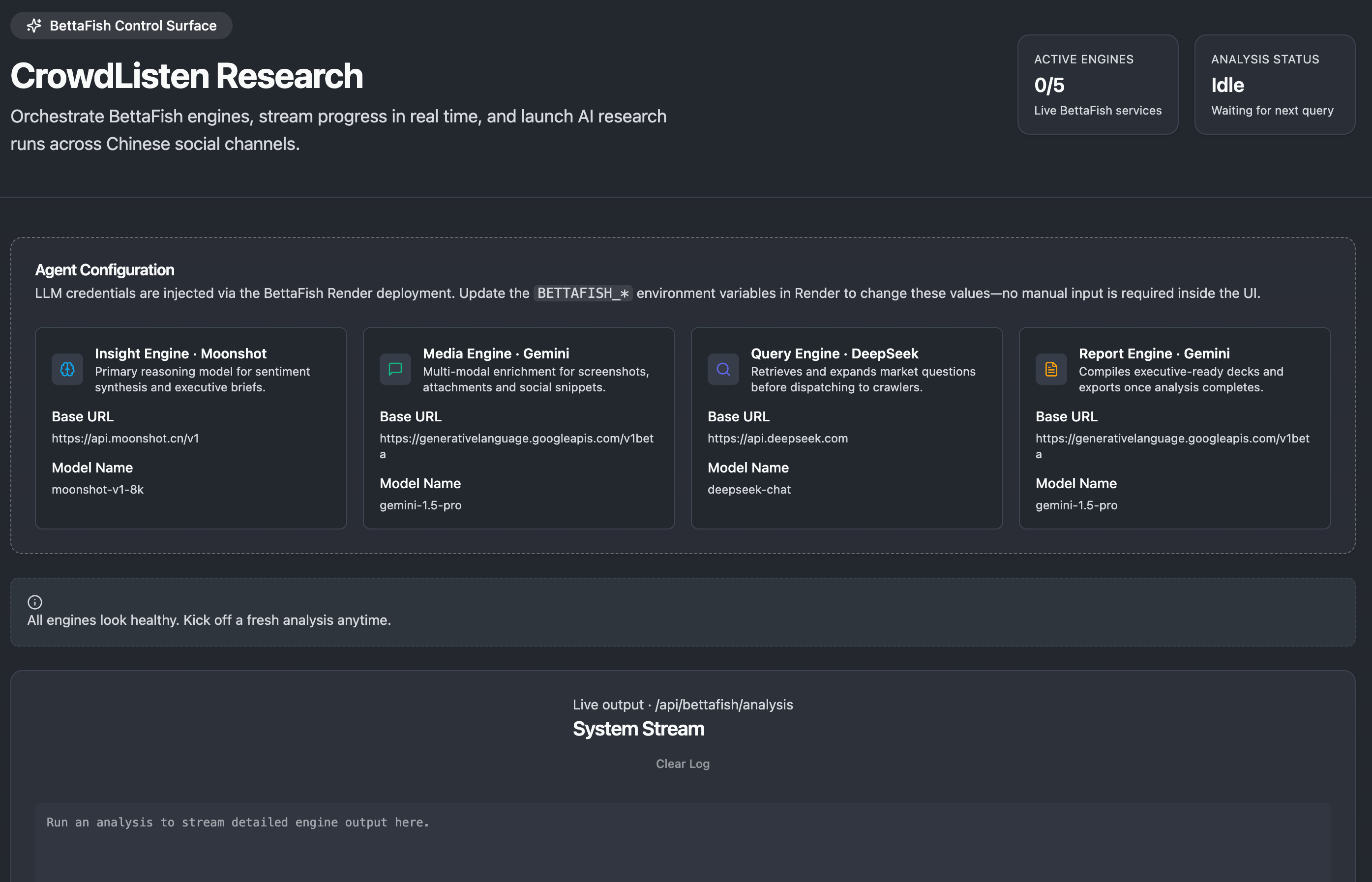
CrowdListen’s research infrastructure is built around a sophisticated orchestration system that coordinates multiple specialized AI engines. The Research Command Center provides users with a unified interface to launch complex analysis workflows while monitoring the progress of different analytical engines in real-time.
Our system utilizes the BettaFish Control Surface, which orchestrates various AI engines including the Insight Engine for sentiment analysis, Media Engine for multimodal content processing, Query Engine for information retrieval, and Report Engine for generating executive-ready reports. This modular architecture allows for scalable analysis that can adapt to different research requirements.
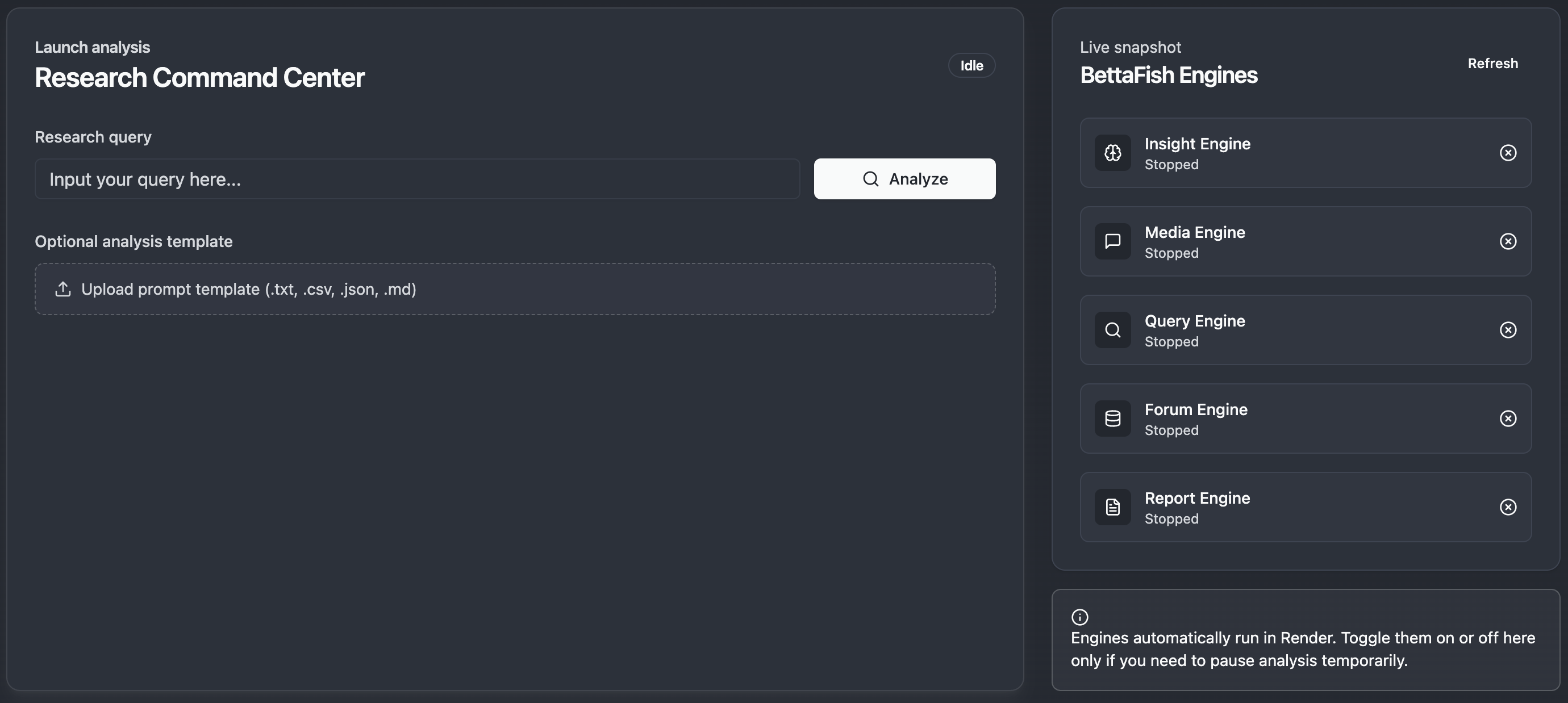
The research interface enables users to input complex queries and optionally upload analysis templates to guide the investigation. The system then automatically determines which analytical capabilities to deploy, processing everything from web search and specialized platform data collection to multi-layered content analysis and synthesis.
This integrated approach represents a significant advancement over traditional social media monitoring tools, enabling researchers to conduct comprehensive investigations that would typically require weeks of manual work in a matter of minutes while maintaining the depth and rigor of human-led research.
Case Study: Google NotebookLM Analysis
To demonstrate Crowdlistening’s capabilities in product intelligence, we conducted a comprehensive analysis of user sentiment regarding Google’s NotebookLM tool. This case study showcases our platform’s ability to extract nuanced insights about emerging AI tools and understand user adoption patterns.

When analyzing user sentiment around NotebookLM, our system provided a comprehensive overview showing that customer feedback indicates NotebookLM is effective for information synthesis and content generation, particularly in educational settings. However, users express concerns about the lack of persistent chat history, word count limits, and potential biases in the auto-generated podcast feature. Approximately 56% of users have a positive sentiment, praising its summarization capabilities and educational applications, while 34% express negative sentiment due to usability issues and accuracy concerns.
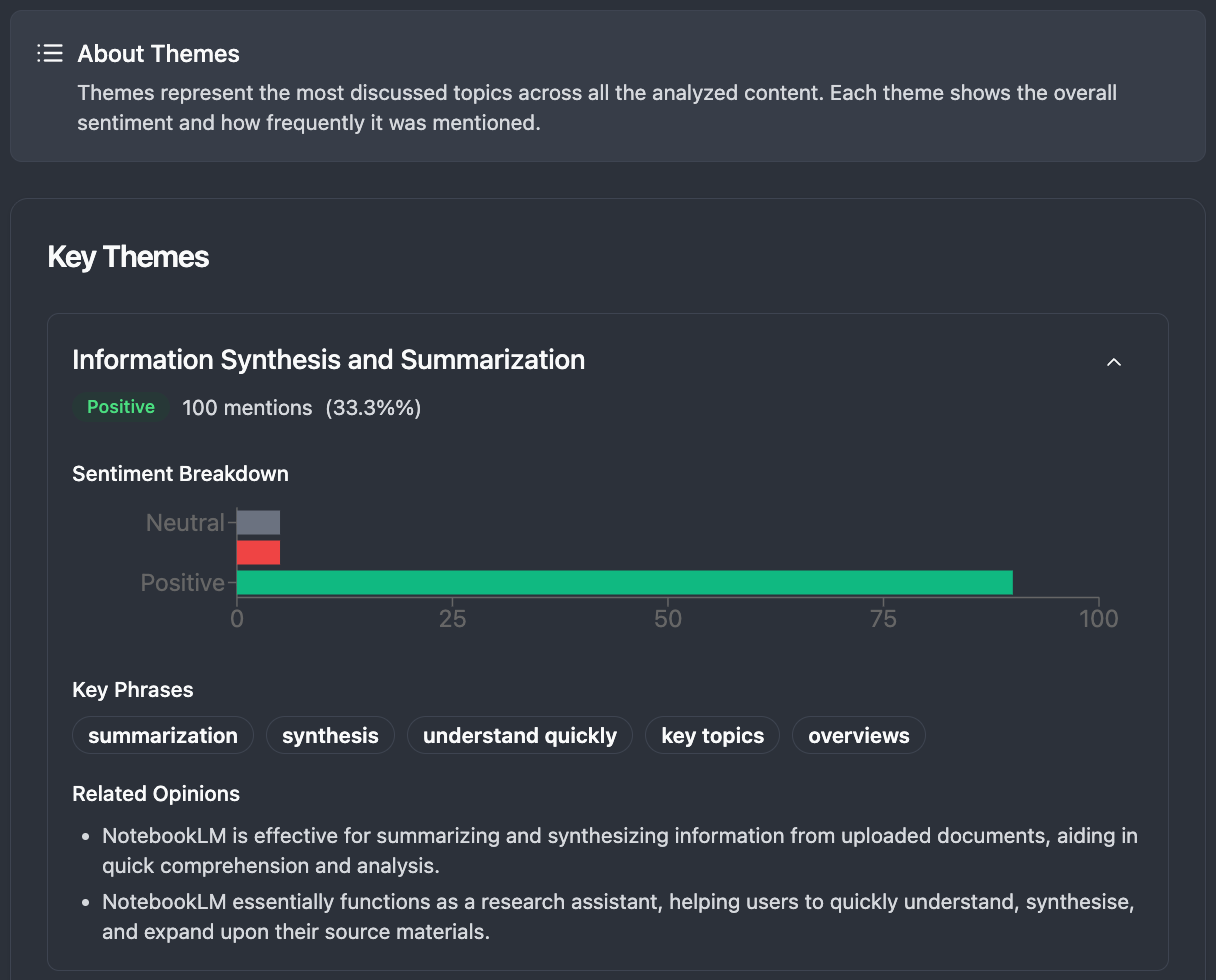
Our thematic analysis reveals that Information Synthesis and Summarization is the most discussed topic, with 100 mentions representing 33.39% of all conversations. The sentiment breakdown shows overwhelmingly positive feedback for this core functionality, with users particularly appreciating the tool’s ability to synthesize information from uploaded documents and aid in quick comprehension and analysis.
The detailed sentiment analysis shows specific user opinions, including praise for NotebookLM’s effectiveness in summarizing and synthesizing information from uploaded documents, its utility for creating study guides and educational materials, and its ability to provide citations for generated information to help users verify accuracy and build trust in the tool’s output.
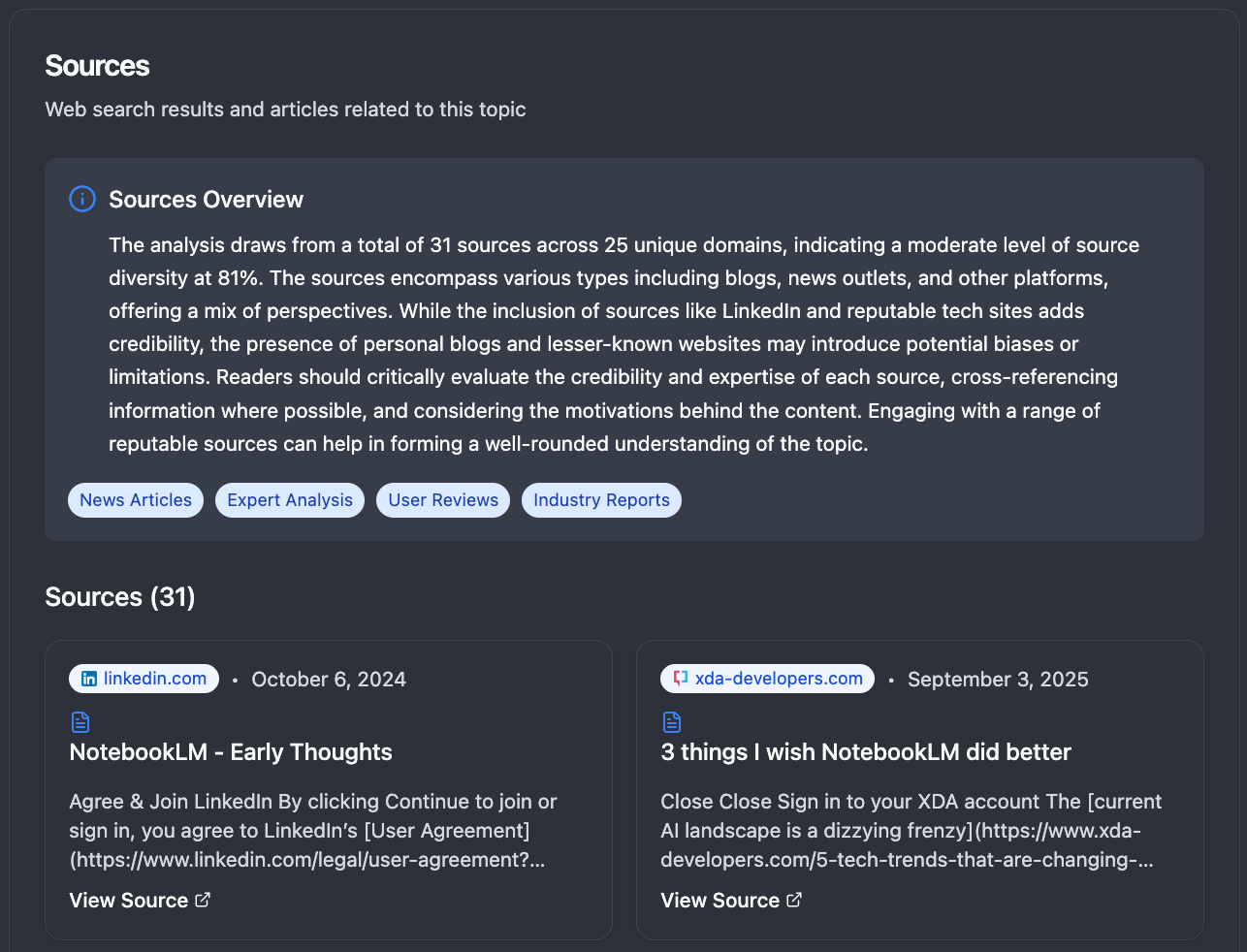
Our analysis draws from 31 sources across 25 unique domains, indicating a moderate level of source diversity at 81%. The sources encompass various types including blogs, news outlets, and other platforms, offering a mix of perspectives. This comprehensive source analysis helps validate the reliability and breadth of our insights.

The platform also identifies related research opportunities, suggesting additional analysis areas such as specific research or writing challenges that NotebookLM helps users overcome, how effectively it addresses information overload, the biggest frustrations users encounter, and whether it has improved research workflows. This demonstrates our system’s ability to not only analyze current sentiment but also identify strategic research directions.
Content Predictor: AI-Powered Engagement Forecasting
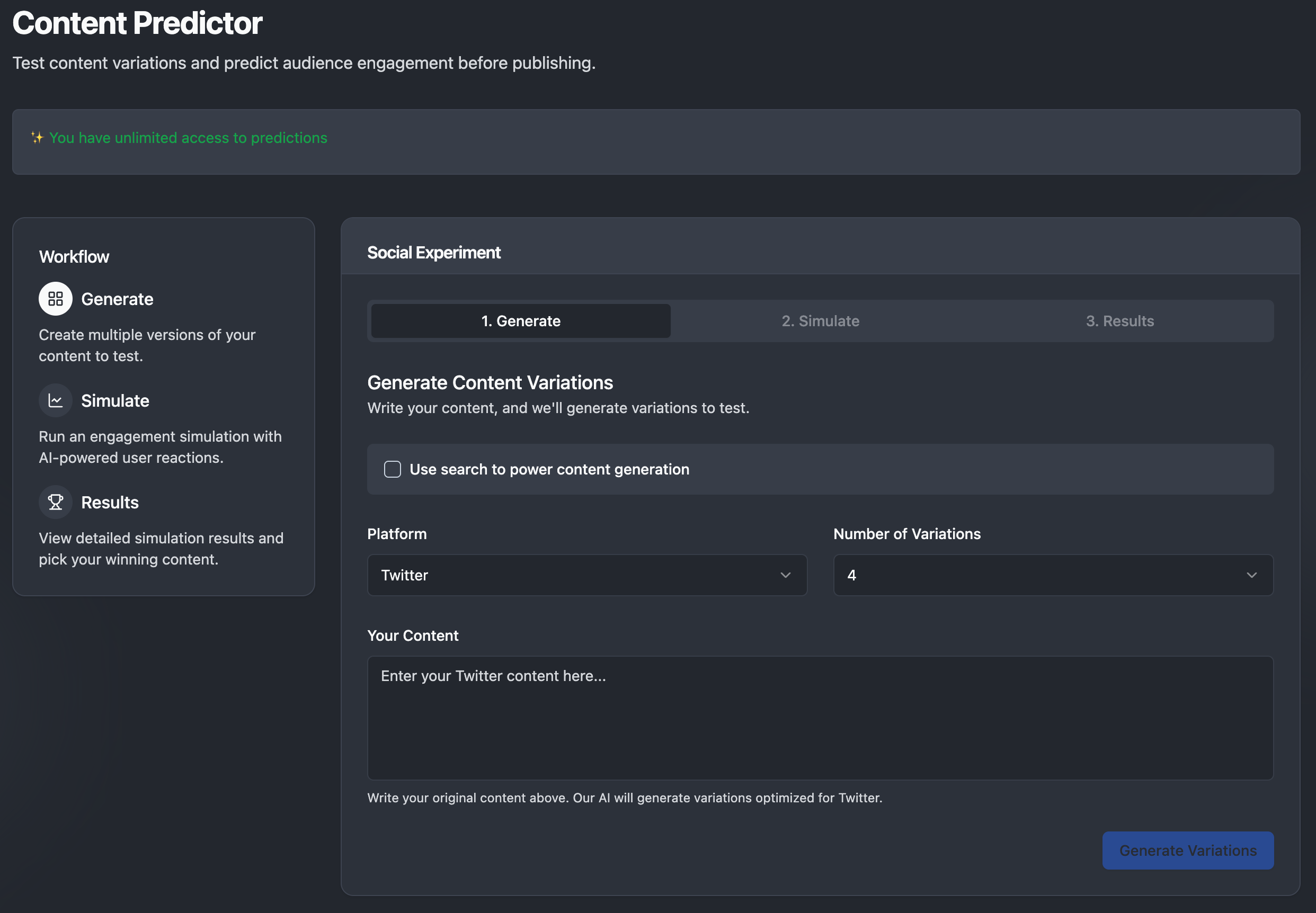
One of our most innovative features is the Content Predictor, which allows users to test content variations and predict audience engagement before publishing. This tool represents a significant advancement in social media strategy, enabling teams to experiment with different messaging approaches without the traditional risks and costs associated with live testing.
The Content Predictor uses a sophisticated three-step workflow. Users begin by generating multiple versions of their content, allowing our AI to create variations optimized for specific platforms like Twitter, Instagram, or LinkedIn. Next, the system runs engagement simulations using AI-powered user reactions that model realistic audience behavior patterns. Finally, users can view detailed simulation results and select the most promising content variations based on predicted performance metrics.
This capability is particularly valuable for brands and content creators who need to maximize the impact of their social media presence. Rather than relying on intuition or conducting expensive A/B tests with real audiences, teams can now validate their content strategies in a controlled environment before committing to publication. The system considers factors such as platform-specific audience behaviors, trending topics, and historical engagement patterns to provide accurate predictions.
The Content Predictor exemplifies our broader mission of transforming social media from a reactive medium to a strategic tool where decisions are informed by data and predictive intelligence rather than guesswork.
Validation and Impact
Our solution has been validated through interviews with major brands like L’Oreal, confirming we drastically cut the time and cost of social media analysis. Crowdlistening enables:
- Rapid response to emerging trends
- Deep understanding of consumer sentiment across demographics
- Identification of microtrends before they become mainstream
- Competitive intelligence at unprecedented scale
The Future of MCP-Driven Research
We believe Model Context Protocols represent the future of specialized LLM applications. As shown in our implementation, MCPs provide a structured way for language models to interact with specialized tools and data sources while maintaining context awareness throughout the analysis process.
This approach is likely to become standard in LLM application development given how effectively it bridges the gap between general-purpose AI and domain-specific functionality. We anticipate seeing more MCP clients (interaction surfaces like Claude’s interface) emerge as this paradigm gains traction.
For social media analysis specifically, this approach creates a fascinating dynamic where AI-driven insights can actually lead structured reporting in terms of timeliness and depth. By processing and analyzing unstructured social data at scale, we can identify emerging trends and public sentiment shifts before they’re covered in traditional reporting.
Credits
This project was developed in collaboration with Madison Bratley, whose expertise in journalism and social media analysis was instrumental in conceptualizing how this technology could transform research methodologies. Additional contributions from Violet Liu in providing valuable usability feedback for our early prototype. I would also like to acknowledge Zhengjin, Cathy, Roy, Ruiwan, Qiping, Tongming and other members on the Creative team at TikTok, who I’ve discussed early conceptions of this idea with.
On Social Intelligence
Crowdlistening represents the next evolution in social listening tools - moving beyond counting mentions to truly understanding conversations at scale. By transforming social media chatter into structured insights, we’re helping brands make more informed decisions faster than ever before.
As noted in “Essence of Creativity,” the real value in AI-powered tools comes not just from generating content, but from helping users find new perspectives and insights. Our platform serves as both an inspiration acquisition tool (accelerating original content production) and a content understanding tool (helping brands better comprehend their audience). By connecting insight data with generation capabilities, we’re creating the kind of breakthrough product that bridges the gap between understanding and action.
📋 Version History
v1.1 • Oct 25, 2025 • View changes • Updated Title
💡 Click “View changes” to see exactly what changed between versions