An analysis of traditional search paradigms and a framework for integrating AI capabilities into content discovery platforms.
The Content Discovery Challenge
Traditional search paradigms face fundamental limitations in today’s information-rich environment. Users often struggle to articulate their information needs precisely, leading to iterative query refinement and incomplete discovery. Current search systems prioritize keyword matching over intent understanding, resulting in high precision for specific queries but poor recall for exploratory or contextual searches.
The challenge extends beyond technical limitations to cognitive ones. Users don’t always know what they’re looking for until they find it, making traditional query-based search inadequate for discovery scenarios. This creates a significant opportunity for AI-enhanced systems that can understand and anticipate user needs rather than simply matching keywords.
Evolution Framework for Search Intelligence
The transformation of search and discovery systems follows a three-stage evolutionary framework that addresses increasingly sophisticated user needs and capabilities. This progression moves from basic content retrieval through enhanced scenario coverage to fundamentally reimagined discovery experiences.
Stage 1: Foundation - Meeting Basic Requirements
The foundational stage focuses on perfecting core search functionality while establishing the infrastructure for more advanced capabilities. Precise Content Location ensures that users who know exactly what they’re looking for can find it efficiently through refined keyword search that delivers accurate results for specific queries. Experience Completeness enhances user interaction through comprehensive search history that enables users to revisit and build upon previous discoveries, intelligent input prediction that accelerates query formulation, and seamless cross-session continuity that maintains context across multiple search interactions.
Recommendation Integration introduces proactive discovery elements that complement traditional search, including contextual suggestions that surface relevant content based on current search behavior, curated entry points that guide users toward high-quality content collections, and algorithmic recommendations that leverage user patterns to suggest potentially valuable discoveries.
Stage 2: Expansion - Covering Diverse Search Scenarios
The expansion stage addresses the limitations of traditional search by supporting more nuanced and complex user needs. Fuzzy Requirements Support enables the system to interpret and respond to ambiguous or incomplete user expressions through natural language processing that understands intent beyond keywords, semantic matching that connects user needs with relevant content even when terminology differs, and contextual interpretation that considers the user’s situation and background when generating responses.
Personalization with Transparency creates tailored experiences while maintaining user understanding and control. The system provides clear reasoning for recommendations that explains why specific content appears relevant, develops adaptive algorithms that learn from user interactions while respecting privacy preferences, and implements granular search capabilities that support both high-level topic exploration and detailed, specific content discovery.
Multi-Granularity Discovery supports different levels of content exploration, from individual article or viewpoint-level recommendations that address specific questions or perspectives, to comprehensive collection-level suggestions that provide structured learning paths or thematic exploration opportunities.
The transformation stage represents a fundamental shift from search as retrieval to search as an intelligent creation and curation platform. Knowledge Association and Generation enables the system to synthesize personalized content that matches individual consumption preferences, connecting disparate information sources into coherent, customized presentations that serve specific user needs and contexts.
Adaptive Content Matching ensures that discovered or generated content aligns with current user capabilities and preferences, including difficulty calibration that presents information at appropriate complexity levels, modality optimization that delivers content in formats best suited to user preferences and contexts, and contextual relevance that considers the user’s immediate goals and longer-term interests.
Dynamic Content Creation addresses gaps in existing content through real-time synthesis that generates answers or explanations when suitable existing content cannot be found, asynchronous content development that creates comprehensive resources for recurring user needs, and collaborative generation that combines AI capabilities with human expertise to produce high-quality, tailored content.
This evolutionary framework recognizes that modern search must progress beyond simple information retrieval to become an intelligent partner in knowledge discovery, learning, and content creation. Each stage builds upon the previous one while introducing fundamentally new capabilities that expand what users can accomplish through search interactions.
Competitive Landscape Analysis
| Platform Type | Strengths | Weaknesses |
|---|
| Traditional Search Engines | Comprehensive indexing, fast retrieval, established user behavior patterns | Limited contextual understanding, poor handling of ambiguous queries, difficulty with exploratory search |
| Recommendation Systems | Personalization capabilities, learning from user behavior, serendipitous discovery | Filter bubble effects, cold start problems, limited transparency |
| AI-Enhanced Platforms | Natural language understanding, conversational interfaces, contextual awareness | Computational costs, accuracy concerns, user trust issues |
Proposed AI Integration Framework
The AI integration framework follows a three-phase approach designed to incrementally enhance search capabilities while maintaining user trust and system reliability.
Phase 1: Query Enhancement
The foundation phase implements LLM-powered query understanding that can interpret ambiguous or incomplete queries, transforming user intent into actionable search parameters. This includes suggesting query refinements and alternatives based on contextual understanding, extracting clear intent from natural language descriptions, and providing contextual query expansion that broadens search scope while maintaining relevance. This phase establishes the groundwork for more sophisticated AI interactions while delivering immediate value to users struggling with traditional keyword-based search limitations.
Phase 2: Content Synthesis
Building on enhanced query understanding, the content synthesis phase develops advanced generation capabilities that summarize multiple sources into coherent overviews, enabling users to quickly grasp complex topics from diverse perspectives. The system generates comparative analyses across different viewpoints, creates personalized explanations based on user background and expertise level, and synthesizes comprehensive answers from distributed information sources. This phase transforms search from simple information retrieval into intelligent content curation that adapts to individual user needs and contexts.
Phase 3: Conversational Discovery
The final phase creates interactive discovery experiences that fundamentally change how users explore information. This includes sophisticated follow-up question generation that guides users toward deeper understanding, exploratory conversation flows that encourage serendipitous discovery, contextual recommendations that surface related concepts and ideas, and learning path suggestions that create structured journeys through complex domains. This phase represents the full realization of AI-enhanced search, where the system becomes a collaborative partner in knowledge discovery rather than simply a retrieval tool.
User Interface Design Recommendations
Progressive Disclosure Architecture
Effective AI-enhanced search interfaces must design for complexity while maintaining simplicity. The progressive disclosure approach starts with simple, high-level answers that provide immediate value while indicating deeper information availability. Clear pathways to more detailed information allow users to drill down based on their specific needs and interests. Topic exploration through related concepts creates natural discovery paths that expand user understanding beyond their original query. Supporting both focused and exploratory search modes ensures the interface adapts to different user intents and discovery styles.
Conversational Elements
Modern search interfaces benefit from integrating chat-like interactions that feel natural and intuitive. Contextual follow-up questions guide users toward more specific or broader explorations based on their demonstrated interests. Maintaining conversation history and context enables the system to build understanding over multiple interactions, creating more personalized and relevant responses. Clarification and refinement capabilities allow users to iteratively improve search results through natural dialogue. Multi-turn information gathering transforms search from isolated queries into collaborative knowledge-building sessions.
Personalization Without Intrusion
Successful AI search systems must balance personalization benefits with user privacy and control concerns. Learning from interaction patterns rather than explicit profiling reduces user burden while building sophisticated understanding of preferences and needs. Transparency into personalization decisions builds user trust by explaining why certain results or recommendations appear. User control over recommendation intensity allows individuals to adjust the system’s proactive behavior based on their current goals and contexts. Balancing novelty with relevance ensures that personalization enhances rather than constrains discovery opportunities.
Technical Implementation Strategy
Hybrid Architecture Approach
The most effective AI-enhanced search systems combine traditional infrastructure with advanced AI capabilities rather than replacing existing systems entirely. Maintaining fast keyword-based retrieval for precise queries ensures excellent performance for straightforward information needs. Layering AI enhancement for ambiguous or exploratory searches adds intelligence where it provides the most value. Implementing fallback mechanisms for AI system failures ensures reliability and user trust. Optimizing for both speed and understanding creates systems that excel across diverse use cases and user needs.
Vector Search Integration
Semantic search capabilities through vector embedding technology enable understanding of meaning beyond keyword matching. Document embedding for content similarity allows the system to find conceptually related information even when specific terminology differs. Query embedding for intent matching translates user needs into semantic space for more accurate retrieval. Contextual embedding updates based on user interaction enable the system to learn and adapt over time. Multi-modal embedding for diverse content types creates unified search experiences across text, images, audio, and other media formats.
Real-time Learning Systems
Adaptive systems that improve through use represent a key advantage of AI-enhanced search platforms. Capturing implicit feedback from user interactions provides rich signals about content quality and relevance without requiring explicit user effort. Updating recommendations based on session context enables dynamic adaptation to evolving user needs within single search sessions. Learning from successful discovery patterns helps the system recognize and replicate effective search strategies. Adapting to changing user needs over time ensures long-term relevance and value as user interests and expertise evolve.
Quality Assurance Framework
Content Accuracy Measures
Maintaining content quality in AI-enhanced systems requires comprehensive validation approaches. Source attribution and verification ensure that generated content maintains clear provenance and accuracy standards. Fact-checking against authoritative sources provides additional validation layers for critical information. Confidence scoring for generated responses helps users understand the reliability of AI-generated content. Human review workflows for critical information ensure that important decisions receive appropriate oversight and validation.
User Experience Validation
Measuring the effectiveness of AI-enhanced discovery requires sophisticated assessment approaches beyond traditional engagement metrics. Task completion rate analysis reveals whether users successfully achieve their information goals. User satisfaction with discovery outcomes provides direct feedback about system value and effectiveness. Time-to-insight metrics measure how quickly users can find valuable information and understanding. Exploration depth and breadth measurement assesses whether the system successfully encourages beneficial discovery behaviors.
Bias Detection and Mitigation
AI systems require ongoing monitoring to ensure fair and equitable information access. Search result ranking and selection algorithms must be regularly audited for potential biases that could disadvantage certain topics, perspectives, or user groups. Content recommendation algorithms need continuous evaluation to prevent filter bubble effects that limit user exposure to diverse viewpoints. Personalization filter effects require monitoring to ensure that customization enhances rather than constrains user discovery opportunities. Representation across different user groups must be regularly assessed to ensure equitable access and value delivery.
Strategic Implementation Roadmap
| Quarter | Focus Area | Key Deliverables |
|---|
| Q1: Foundation | Basic AI Integration | LLM query enhancement, semantic search deployment, content quality frameworks, pilot user testing |
| Q2: Enhancement | Advanced Features | Conversational discovery, personalization algorithms, content synthesis capabilities, infrastructure scaling |
| Q3: Optimization | Data-Driven Improvement | Algorithm refinement, UI enhancement, advanced quality assurance, expanded content integration |
| Q4: Scale | Full Deployment | Complete AI-enhanced search, comprehensive testing, advanced analytics, next-generation planning |
AI Book Search Prototype
An intelligent book search system that understands your needs and provides personalized recommendations using GPT-4o.
Product Rationale
The Problem
Traditional book discovery suffers from several fundamental limitations that prevent readers from finding content that truly resonates with their needs and interests. Conventional search relies on exact keyword matches, failing to understand the nuanced intent behind user queries and missing opportunities for meaningful discovery. Most systems provide broad, one-size-fits-all suggestions without considering the user’s specific emotional state, learning goals, or contextual needs, resulting in generic recommendations that often miss the mark.
People frequently remember books by fragments rather than complete details, recalling a powerful quote, a character trait, or an emotional impact but struggling to translate these memories into findable search terms. Current systems cannot distinguish between fundamentally different user intents, such as needing practical advice versus wanting to explore ideas versus seeking emotional catharsis, leading to misaligned recommendations that frustrate rather than inspire.
The Vision
AI Book Search represents a paradigm shift from information retrieval to intelligent content curation. Instead of searching for books, users can now search through their intentions, memories, and needs. The system acts as a knowledgeable librarian who understands not just what you’re asking, but why you’re asking and how to help you discover content that truly resonates with your current situation and interests.
Core Innovation
The breakthrough lies in intent-aware content discovery that combines semantic understanding with contextual curation. The AI interprets the deeper meaning behind queries, not just surface keywords, enabling understanding of complex, nuanced requests. Recommendations adapt to user intent categories, providing contextually relevant content that matches both explicit needs and implicit desires.
Memory-based discovery allows users to search using fragments of memory, including quotes, character descriptions, and plot elements, transforming partial recollections into successful book discoveries. Progressive learning journeys ensure that content cards form logical progressions from foundational to advanced concepts, supporting sustained learning and exploration. Multi-modal content integration seamlessly combines books, podcasts, articles, and quotes into cohesive recommendations that provide comprehensive coverage of user interests.
Target Impact
The system aims to dramatically reduce discovery friction, transforming the typical 15+ minute browsing session into instant, relevant recommendations that immediately connect with user needs. Enhanced learning outcomes result from curated progressions that build knowledge systematically rather than randomly. Emotional resonance ensures that content matches not just intellectual interests but emotional and contextual needs, creating more meaningful reading experiences. Democratizing expert curation provides every user with personalized librarian-level guidance, regardless of their access to professional recommendation services.
Implementation Strategy
Design Philosophy
Rather than retrofitting AI onto traditional search, the system builds entirely around LLM capabilities to create fundamentally new discovery experiences. Query understanding through GPT-4o analyzes user intent before any content retrieval, ensuring that recommendations address actual needs rather than surface keyword matches. Contextual generation creates content cards based on analyzed intent rather than pre-stored data, enabling dynamic responses that adapt to specific user contexts.
Progressive disclosure reveals information in logical layers, moving from intent analysis through content generation to card rendering. Simple queries receive focused responses while complex topics get comprehensive exploration, ensuring appropriate depth without overwhelming users. Debug mode availability for developers supports system understanding and continuous improvement of the AI decision-making process.
Modular component design ensures that each system element has a single responsibility, creating maintainable and extensible architecture. Type-safe data structures using Pydantic provide reliable data handling, while isolated AI interactions with fallback handling ensure system resilience. Reusable, stateless rendering functions support consistent user experience, and pure orchestration between components maintains clean system architecture.

Technical Implementation
The core technology stack centers on Streamlit for rapid prototyping and clean UI development, enabling quick iteration and user testing. OpenAI GPT-4o provides sophisticated query analysis and content generation capabilities that understand nuanced user intent. Pydantic ensures type-safe JSON processing that maintains data integrity throughout the system. Design for Streamlit Cloud deployment with environment variable configuration supports scalable hosting and easy maintenance.
Key technical decisions prioritize AI-generated content over database search to enable understanding of nuanced, contextual queries that wouldn’t match traditional database keywords. This approach allows creative, synthesized recommendations that combine multiple sources while eliminating the need for massive content databases in the prototype phase. The system provides immediate value without complex data ingestion pipelines, though this creates trade-offs with less precision for specific book details while providing higher relevance for intent-based discovery.
Intent-category classification into seven predefined categories before content generation provides structured understanding of user needs and enables category-specific prompt engineering for better results. This creates predictable, testable system behavior while allowing targeted improvements per intent type. Implementation through a two-stage LLM pipeline with structured JSON responses ensures reliable and interpretable results.
Dynamic card generation produces one to five content cards based on query complexity, ensuring that simple queries receive focused, direct answers while complex topics benefit from multi-perspective exploration. This approach avoids overwhelming users with irrelevant content while creating natural learning progressions that support sustained engagement.
Component-based UI design builds interfaces from reusable, type-specific content cards that support diverse content types including books, podcasts, quotes, and themes. This enables consistent styling across different recommendation types while facilitating easy extension for new content types and providing better responsive design capabilities.
System Architecture
The data flow follows a clear progression from user query through intent analysis to content generation and finally UI rendering. Raw user queries captured via Streamlit undergo GPT-4o analysis that classifies query type and intent category. Category-specific prompts then generate relevant content cards, with Pydantic models ensuring type safety and structure. Dynamic card components render based on content type, while graceful fallbacks at each stage maintain system reliability even when individual components encounter issues.

Features and Capabilities
Smart Query Analysis
The system includes sophisticated specific book detection that identifies when users ask about particular titles, enabling targeted responses with detailed information about known works. Intent classification categorizes general queries into seven distinct types that cover the spectrum of user needs and discovery patterns.
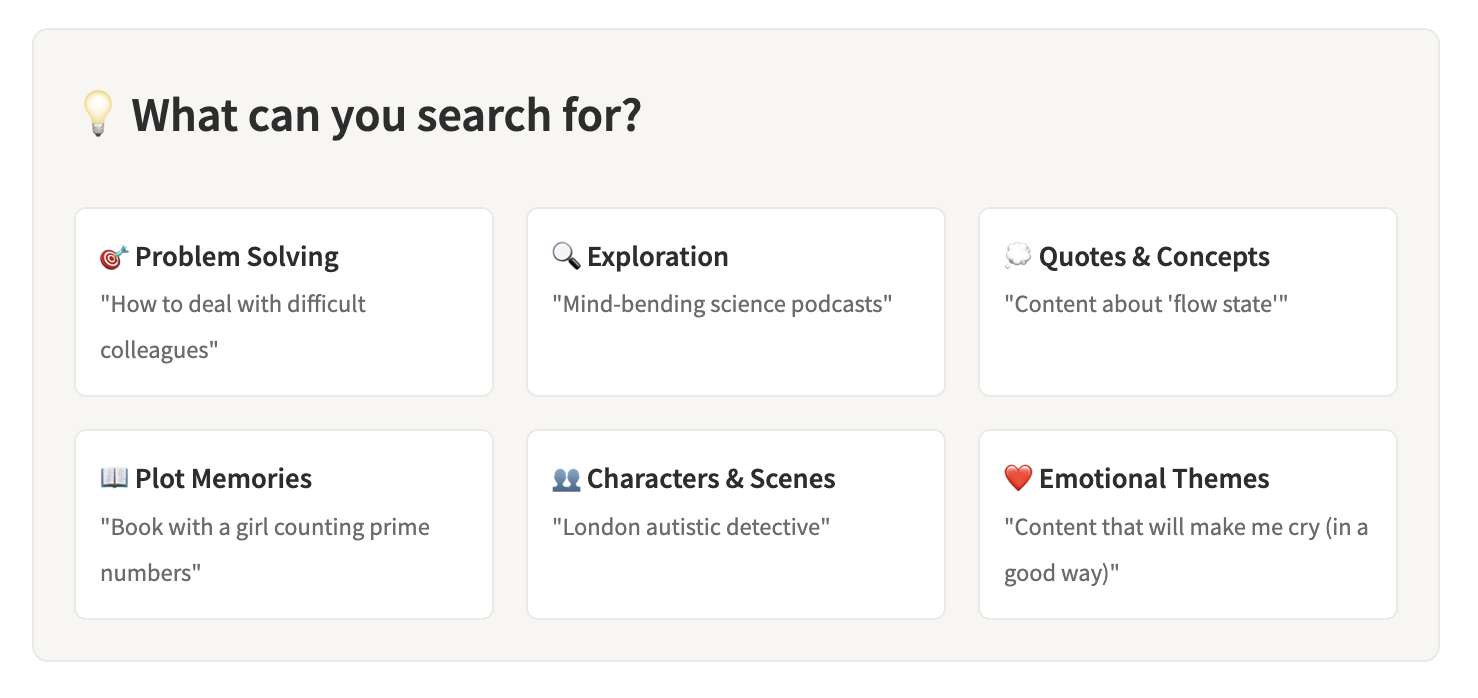
Problem-solving queries like “How to deal with difficult colleagues” receive practical, actionable recommendations focused on applicable knowledge and skills. Exploration and discovery requests such as “Mind-bending science books (not too technical)” generate curated selections that balance intellectual challenge with accessibility. Quote and concept memory searches like “Books about ‘flow state’” help users rediscover influential ideas and their sources.
Plot fragment memory searches such as “Book with a girl counting prime numbers” transform partial story recollections into successful identifications. Character and scene description queries like “London autistic detective” leverage memorable details to find specific works. Emotional and thematic searches such as “Books that will make me cry (in a good way)” connect users with content that matches their desired emotional experience. Comparative searches like “Like Harry Potter but for adults” help users find similar works that match their established preferences while introducing new elements.
Dynamic UI Components
Responsive card design adapts to different content types with distinct visual approaches for quotes, summaries, recommendations, and themes. Book recommendation cards provide rich information including relevance scores and detailed reasoning that helps users understand why specific books match their needs. Quote cards feature special formatting with book attribution and page numbers that enable easy reference and verification. Work-in-progress components with preview data demonstrate planned features and gather user feedback for future development.
AI-Powered Responses
Real GPT-4o integration ensures sophisticated query analysis and content generation that understands complex user intent and context. Structured JSON responses rendered into beautiful UI components provide consistent, reliable user experiences. Fallback handling for API errors ensures system reliability even when external services encounter issues. Debug mode enables understanding of query analysis processes, supporting system improvement and user education about AI decision-making.

Technical Details and Customization
The system employs flexible data models including QueryType classifications for specific books versus general queries, UserIntentCategory definitions covering seven predefined categories, and ContentCard systems with type-specific rendering capabilities. BookRecommendation models provide rich information with reasoning, while PlaceholderFeature components support future development.
API integration utilizes OpenAI GPT-4o for all AI processing with structured JSON responses and Pydantic validation ensuring data integrity. Error handling and fallback responses maintain system reliability, while temperature controls optimize output for different use cases and user needs.
User interface features include custom CSS styling with gradients and animations that create engaging visual experiences. Responsive card layouts adapt to various screen sizes and content types. Debug mode supports development and troubleshooting, while comprehensive loading states and error handling ensure smooth user experiences even when systems encounter difficulties.
Future Development and Roadmap
Planned enhancements include semantic vector search capabilities that leverage advanced embedding-based approaches for even more sophisticated content discovery. User preference learning from search history will enable increasingly personalized recommendations that improve over time. Book database integration will provide access to real book data and availability information, enhancing the practical utility of recommendations.
Social features will enable sharing and collaborative recommendations, creating community-driven discovery experiences. Mobile optimization through progressive web app features will extend access across devices and usage contexts. The modular architecture supports continuous enhancement and experimentation with new recommendation techniques while maintaining stable, high-quality user experiences.
The system represents a foundation for increasingly sophisticated content discovery applications that understand and serve individual user needs through intelligent, adaptive technology. As user data accumulates and understanding of content consumption patterns improves, the system will evolve to provide even more valuable and relevant discovery experiences that genuinely enhance rather than simply automate the content discovery process.
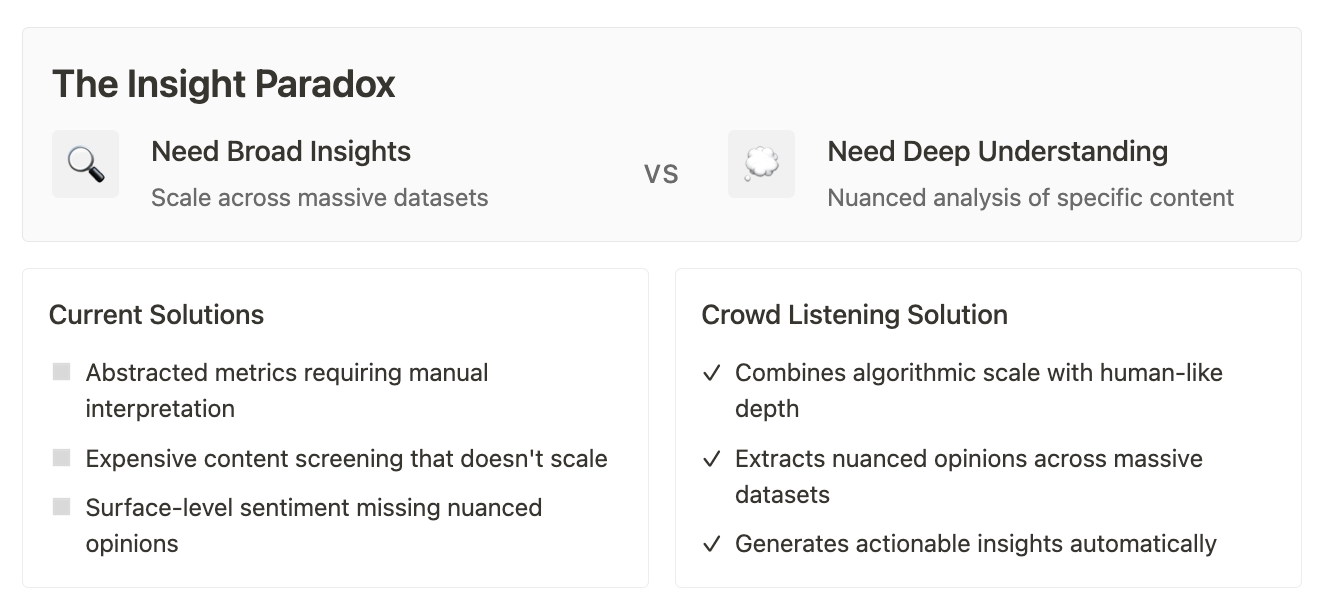
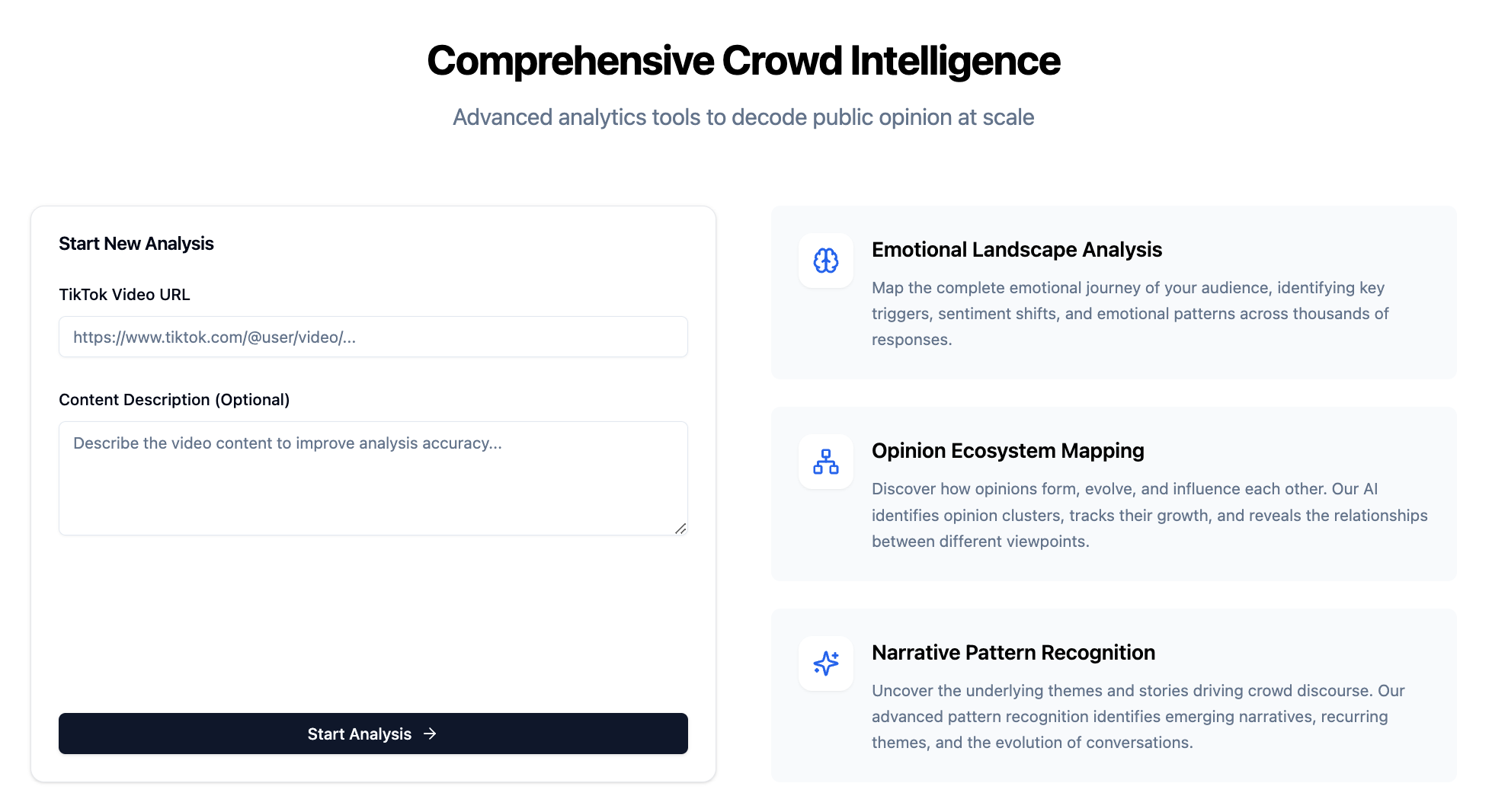
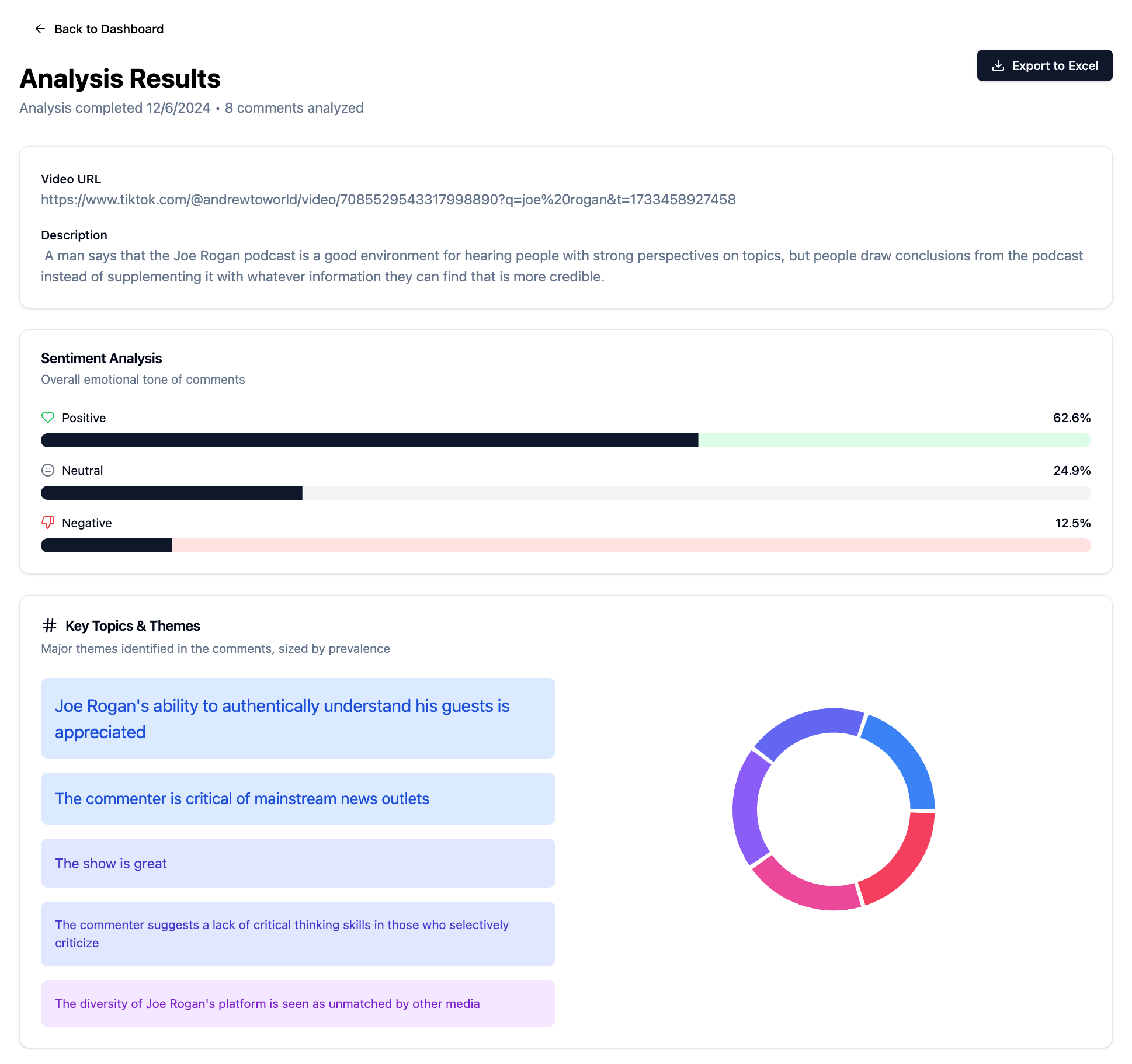
 TikTok’s Insight Spotlight interface showing AI-generated analysis - a product I contributed to while at TikTok
TikTok’s Insight Spotlight interface showing AI-generated analysis - a product I contributed to while at TikTok